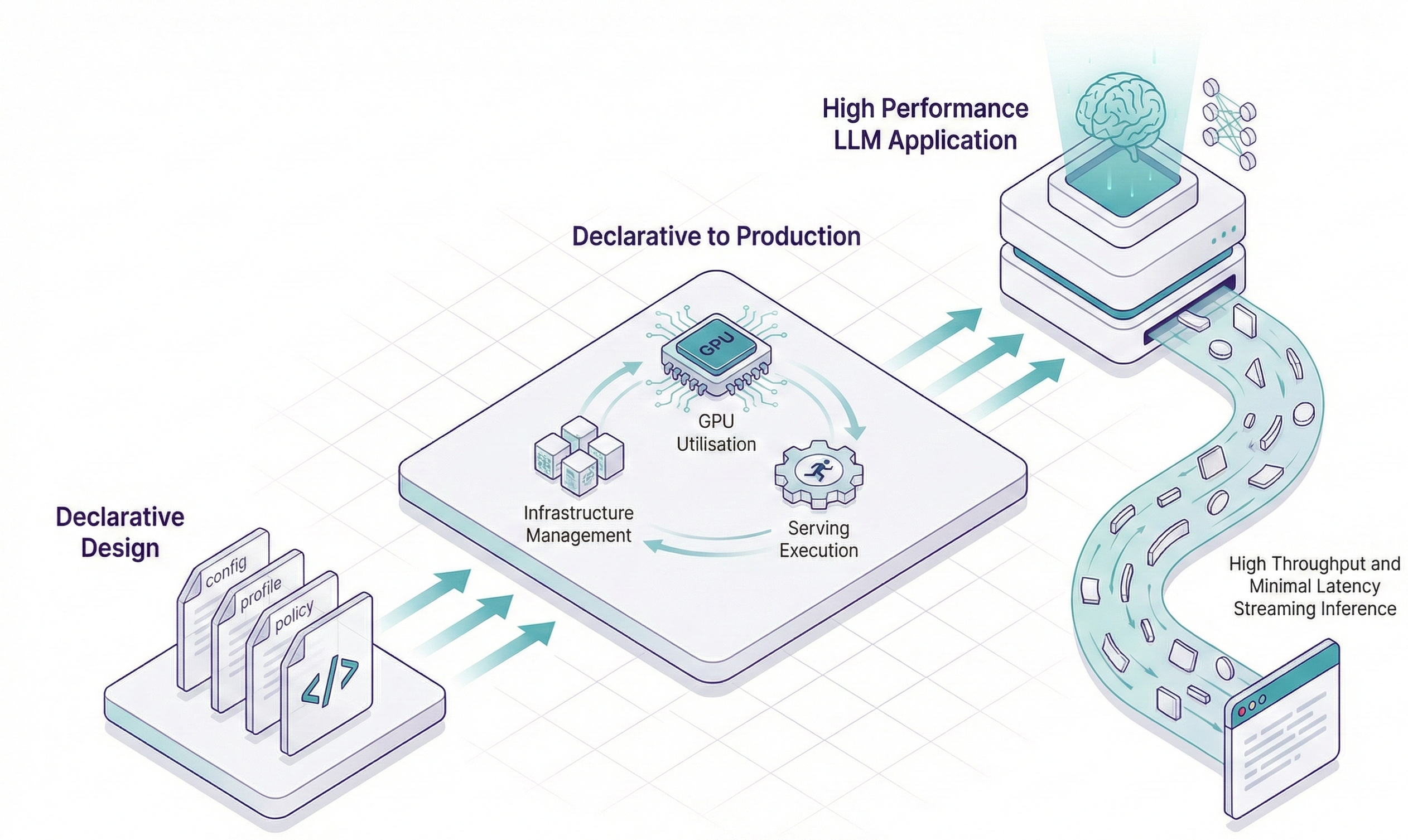
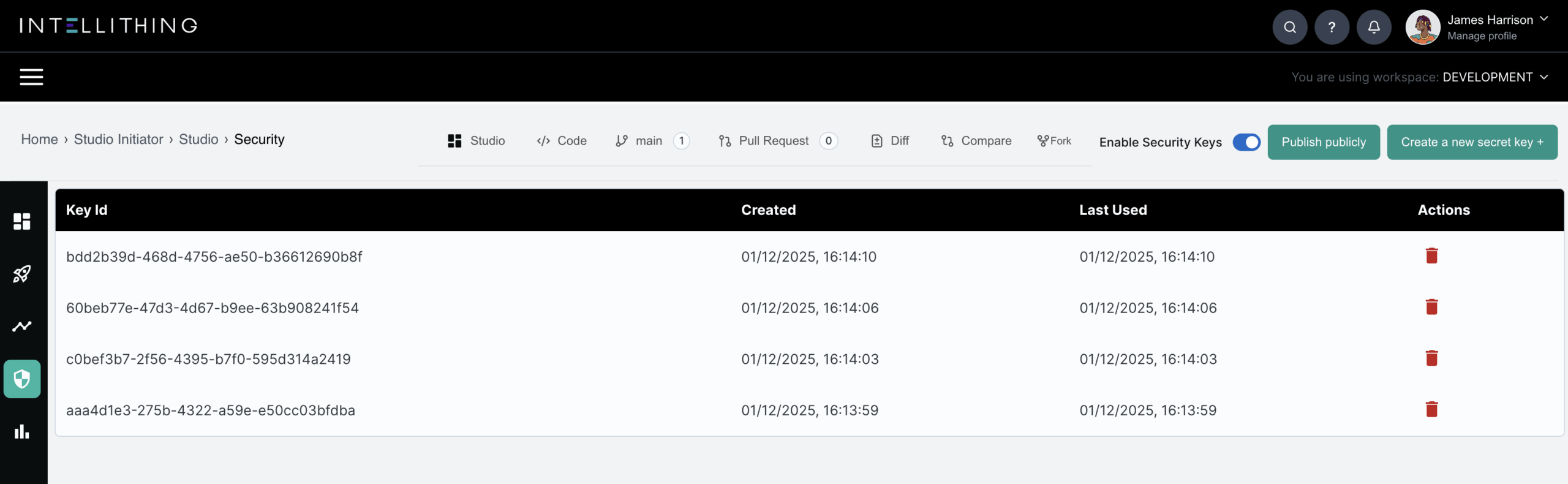
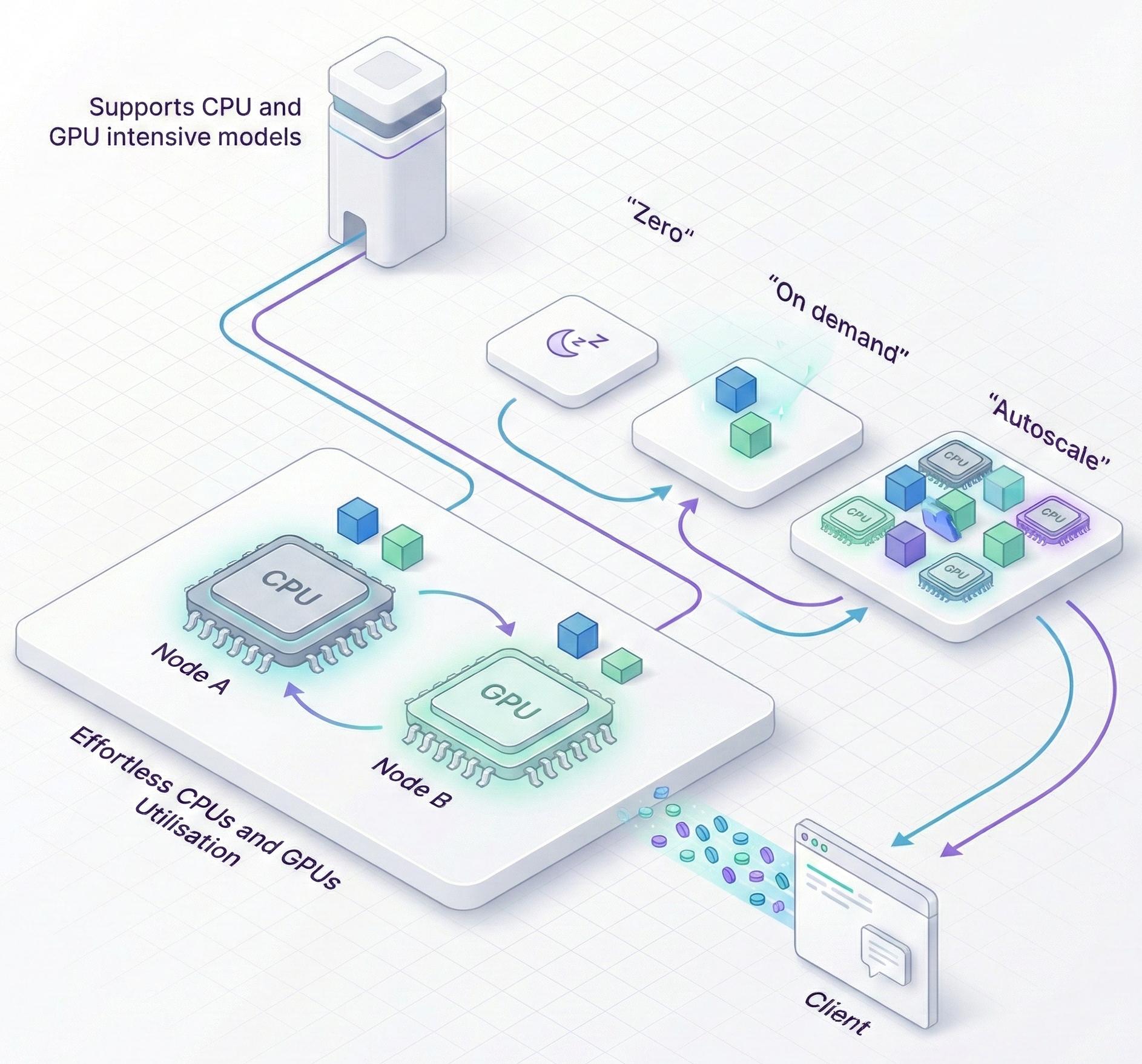
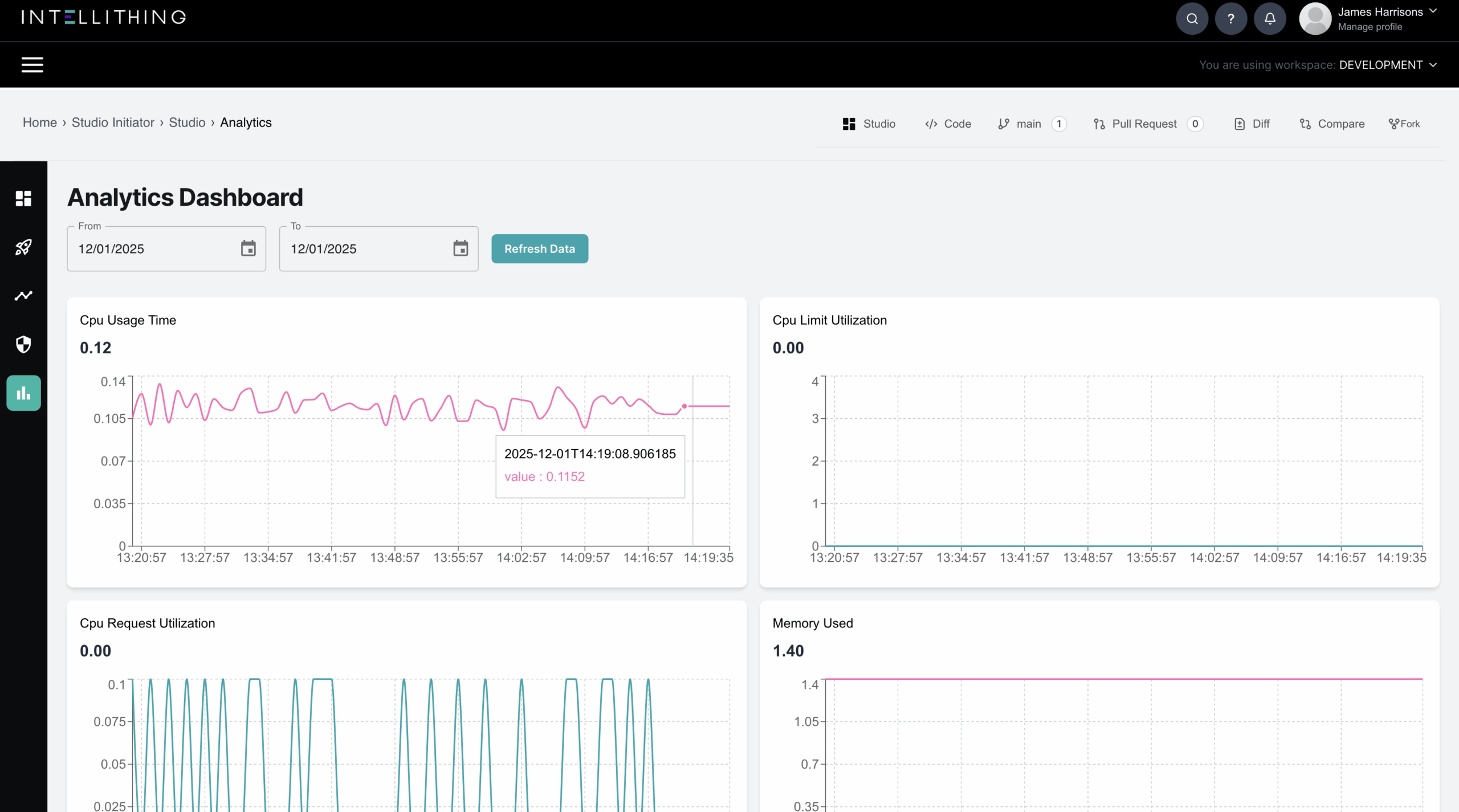
INTELLITHING automatically provisions enterprise-grade API credentials for every application you deploy, including inference endpoints. Each deployment is secured with a unique public and private key pair, enabling signed, verifiable requests and robust service to service trust without custom security engineering.
Keys are generated, stored and governed within your VPC, giving teams a secure default for authentication, easy rotation, and clear auditability for every external or internal API call.